How many SFU layers does daily supports?

by using camSimulcastEncodings, how many SFU layers we can write? can we write layer 0, layer 1, layer 2, layer 3
Best Answers
-
Hi again, @svm_agilis! Great question.
The short answer is that theoretically you can write as many SFU layers as you want. I’d have to get back to you on the practical answer, unless you want to kick the tires at it yourself. But one thing is for certain: more layers will always open up at least the possibility of greater bandwidth consumption, particularly on the sender side.
If you’re interested in learning more, here’s the longer answer—including the pretty excellent ability Daily makes available to subscribe users to specific layers:
First, a little background: Simulcast layers are available by default whenever you’re in SFU mode. Daily triggers SFU mode automatically as soon as five or more people are on a call. But you can also opt to manually enter SFU mode for fewer users by calling `setNetworkTopology()`:
By default, Daily automatically manages three layers for desktops (layers 0, 1, and 2) and two for mobile (layers 0 and 1). Here’s a table showing our defaults’ maximum bitrates and frames rate along with their resolution:
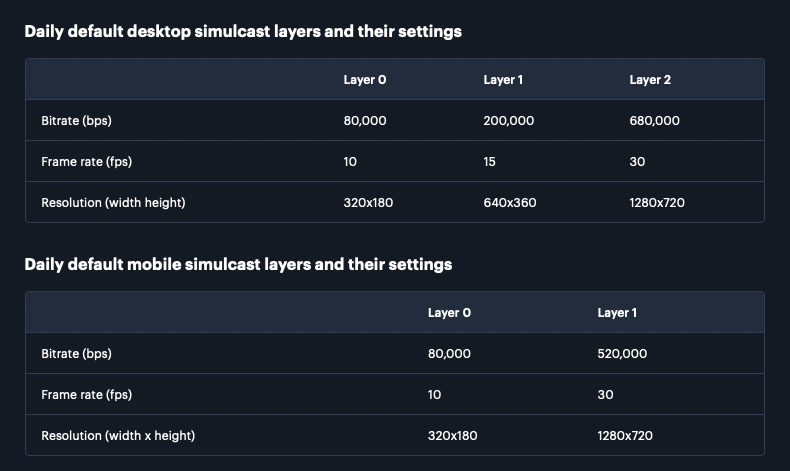
But as you probably know, you can override those defaults by referencing
camSimulcastLayersproperty of thedailyConfigobject, and passing in an array of your own desired layers. You’d need to set each layer’smaxBitrate,maxFramerate, andscaleResolutionDownByvalues. (The maximum frame rate and resolution is established by the paralleluserMediaVideoConstraintsproperty ondailyConfig; see)What I think is especially cool about Daily’s handling of simulcast layers is that you have control not only on the publisher/sender side, but on the subscriber/receiver side as well. You can either pass a `receiveSettings` object to the `join()` method, or make a call to `updateReceiveSettings()` at any point during the lifetime of a call, and specifically request a particular simulcast layer.
For example, to set a specific layer for all participants upon joining a call, you could write something like:

Alternatively, you can specific a particular participant ID in place of `base`, and set the value for a specific user. The `updateReceiveSettings()` method works the same way:
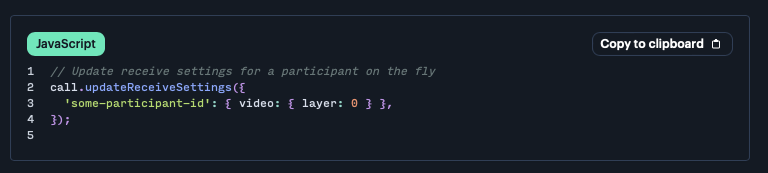
The important thing to note, as it says in our docs ( is that if you subscribe a user to a higher layer than is currently available, the user will receive the best-available layer.)
Finally, fuller details on all of this are in the "Simulcast layer control" section from our guide to call scaling:
I hope you found this useful! I’m interested to hear more about your specific use case, and to keep discussing this topic further.
3 -
@svm_agilis how was it that you added the 480p layer? If you pass in any value to
camSimulcastEncodings, that will be the extent of your simulcast layers. I'm guessing you added just the 480p one? If you want the standard 180, 360, and 720p layers, you have to add those, too.0

Answers
-
Hi @svm_agilis -- you might have seen I posted a comment on this thread. Somehow, in editing it, it disappeared. I'll rewrite and repost here shortly.
0 -
Hi @karl
Thank you so much for the comments 🙂
at present I use 3 SFU layers 180p, 360p and 720p. I have added another layer of 480p. and changed SFU layers to 180p, 360p, 480p and 720p. I have also updated kbs value in setBandwidth method. but I could see that the highest possible layer sending is only 480p not 720p. can you please tell me is there a way to send 4 layers?
0 -
Hi, the limitation is the browser. Chrome, Safari, and Edge all support a maximum of three simulcast layers. I don't think any of the browser vendors have any plans to increase the number of layers they support. But @vr000m may have more information about that.
2 -
@kwindla is correct, Chromium WebRTC based systems can just do 3 simulcast layers. Theoretically, there is no limitation in the WebRTC API and our SFUs. The main reason to support more layers was: to capture landscape and portrait modes, 5 layers, 3 for landscape, 2 for mobile would help the SFU select the correct orientation to send to the downstream participant.
However, it is cheaper computationally to scale and crop at the receiver than encode the video 5 times in different orientations, resolutions (in the above example).
1 -

